Remote Procedure Calls (RPCs) are a widely used primitive for communication in distributed applications. In short, they allow a client the ability to invoke a function on a remote server. gRPC, REST, Apache Thrift, and Cap’n Proto are just some of the ways that RPCs are used today. However, RPCs only allow for client-server communication patterns. RPC Chains from Microsoft Research are meant to address that.
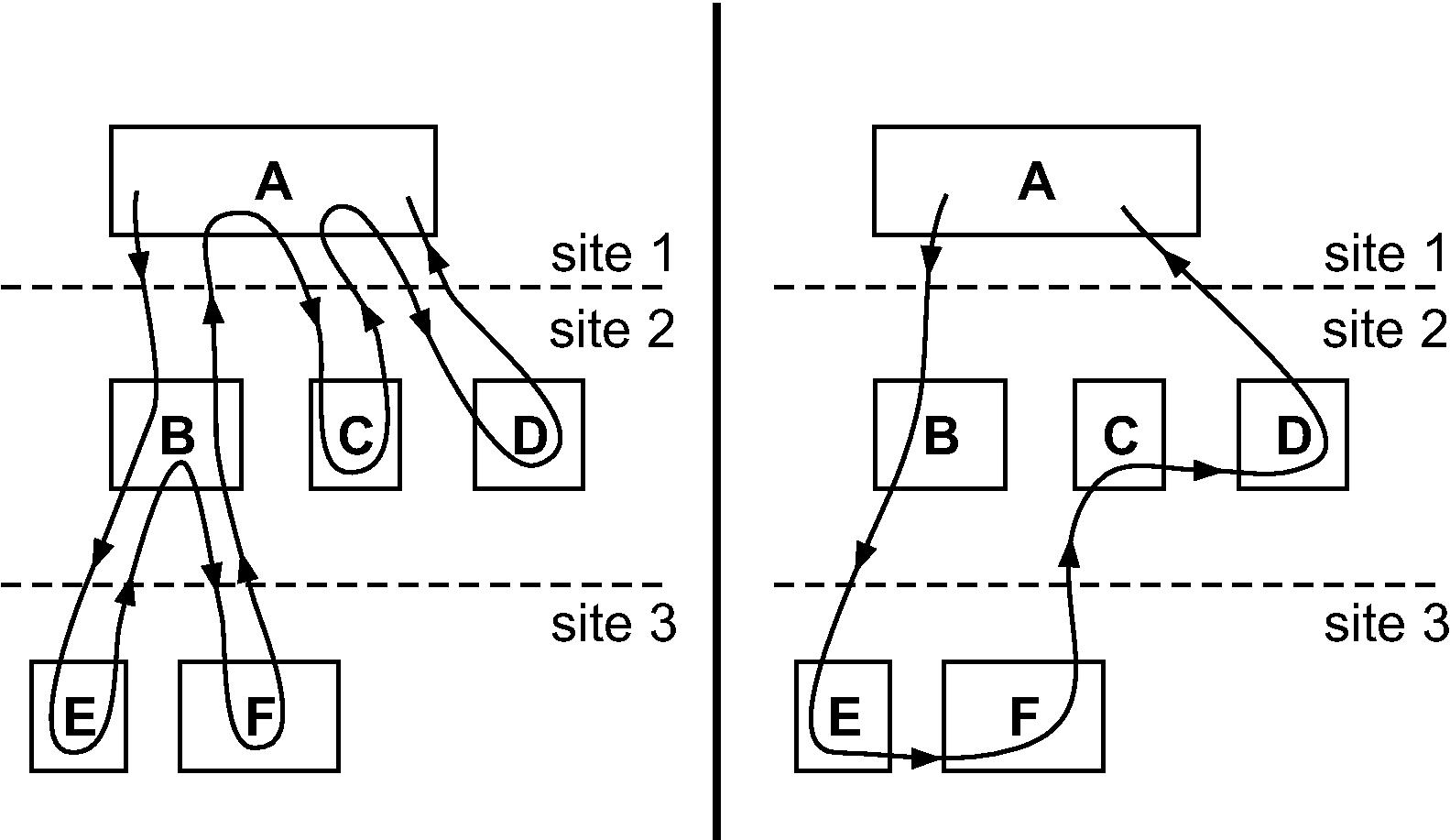
Execution Flow of regular RPCs (left) vs RPC Chains (right)
Rather than issue all requests from the client, along with every request, the client attaches some chaining logic that runs after the RPC is executed. This chaining logic decides where the request should go to next and what RPC should be executed. By building these chains, unnecessary network hops can be avoided, and it can be possible to save on both latency and bandwidth. In a wide-area setting, the latency benefits can be especially nice when a request from one data center needs to execute some logic in a few services in a second, flow to a third, and come back to the client.
Chaining Mechanism
Some interesting questions come up when building RPC chains:
- How is chaining logic transmitted and execute?
- How do we let a server issue an RPC chain to service another RPC chain?
Executing Chaining Logic
The paper addresses this problem by pushing all chaining logic to a repository, and having servers download and compile the code on-demand. Since the logic is written in C#, it’s possible to JIT compile the code and cache it dynamically. However, the actual developer experience is still an important question here. Do we need language support to make writing chainging functions seamless? How does the code get to the repository in the first place? All of these problems are solvable, but it raises the question of how much effort should be placed into solving these problems at other layers.
These days we might use Javascript or WebAssembly for chaining logic, but the mechanics of the system would really be identical to the paper.
Sub-RPC Chains
To allow the implementation of an RPC chain utilize another RPC chain, the authors take inspiration from how function calls work. Just like a call stack is used to store state when nesting calls, the RPC Chain implementation maintains a chain stack to maintain per-chain context.
Performance Benefits
As expected, the authors report impressive performance improvements for wide-area communication and copy-type RPCs within a data center. Since Copy operations executed as a chain can avoid shipping data to the client, RPC Chains can reduce overhead and improve overall throughput. In the wide-area experiments, simply avoiding unnecessary data center hops provides some very obvious improvements.
Limitations
There are three problems that I think this paper left for future work: (1) how should we deal with failures? (2) What server or data center do we use to handle a particular RPC in a chain?
The approach taken in the paper to address (1) is to use timeouts. With RPCs, you can tell whether the server is alive by looking at the status of your connection with that server. With chains, you don’t have that luxury. As a result, I’m concerned about the latency impact when failures occur. Maybe RPC chains are only suitable for wide-area requests, whether the destination of each RPC is a data center not a machine, and so the request can be redirected locally when a failure occurs.
The paper pushes responsibility for (2) to the applicaiton. In fact, I suspect that the paper assumes only one data center can be used to handle a particular request, which could be why they assume it is just not a problem. If we know the structure of the chain ahead of time, routing a request is simply an issue of finding the shortest path in a directed graph. However, if we don’t know the structure of the chain (perhaps it varies based off of the results at different stages), then the problem isn’t so straightforward.
Additionally, if we want to determine where to run services or host data to improve wide-area placement, then our problem becomes exponentially large. This is where things get really interesting: scheduling work and migrating data across data centers to minimize latency or bandwidth for distributed applications.
Conclusion
I really liked this paper. It presents a simple, yet significant improvement on the design of remote procedure calls. While the idea or request chains isn’t new, the paper presents a general mechanism for doing this which should be widely applicable, especially for geo-distributed applications.